這篇主要是在說明如何在windows的環境下,
使用eclipse去連結到ubuntu上的hadoop,
將會在下一篇教導大家如何撰寫一個Map/Reduce程式。
在我連結成功之前,在Google上找了不知道多少資料。
但沒有任何一篇是完完全全符合這個案例的!
大部分找到的案例都是,在Windows環境下安裝cygwin,
利用cygwin來模擬出unix環境,然後再unix中架設hadoop,
問題是這樣的案例...根本沒有太大意義,因為是模擬,就只是單純玩玩而已,
所以才打這篇教學,如何在windows真的連結到一台實體的linux server上。
我的本機基本環境如下:
Eclipse 3.6
Windows 7 64bits
實體linux server環境如下:
ubuntu 10.10
hadoop 0.20.2
【步驟一】首先我們得去下載三個檔案,
- hadoop-eclipse-plugin-0.20.3-SNAPSHOT.jar 先下載這個jar檔,並放在eclipse資料夾底下的/plugin資料夾裡面,有人可能會發現,為什麼我們實體server上的hadoop版本是0.20.2,可是我們用的eclipse plugin版本卻是0.20.3,而不是用0.20.2,這是因為0.20.2有問題。(稍後會說明甚麼問題)
- cygwin 第二個下載這個並且安裝起來,安裝過程很簡單,恕不贅述,但或許有人會納悶..為什麼要安裝這個? 這個不是模擬unix嗎? 我們不是要連結到實體的linux server上嗎? 如果懂MapReduce原理的人,可能就會稍微理解,大家可以去看由2位Google Fellow所提出的paper。簡單的說Reduce最後會將結果輸出到本機硬碟上,而這裡的本機是linux,所以會用到一些相關指令是windows沒有的,例如:chown,所以我們得利用cygwin安裝好後裡面/bin資料夾的一些linux指令。
- hadoop 0.20.2 第三個下載hadoop,原因是再eclipse for windows中開發hadoop專案,會用到一些hadoop的jar檔案,並且解壓縮出來,在這篇,還不需要用到,在下一篇進行程式開發,將會用到!
【步驟二】設定環境變數
下載以及安裝完成以後,
請記得設定環境變數,
設定方式如下(不好意思,我的OS是英文版,請大家自行對照自己電腦)
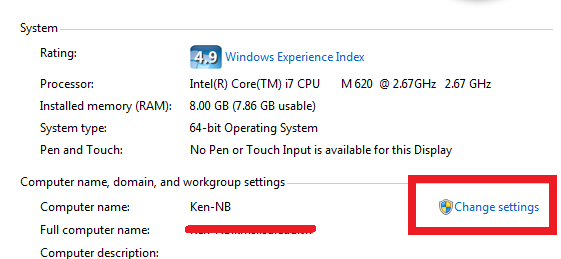
在我的電腦上點選右鍵→點選內容,
會看到下圖(圖一),請點選Change Setting,
 |
| 圖一 |
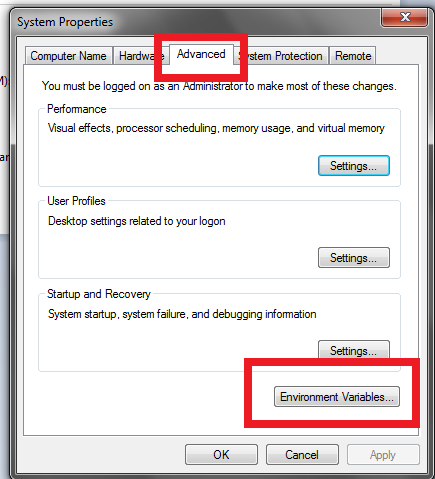
點選完後,會看到下圖(圖二),再點選Advanced,
點選以後再點選Environment Variables
 |
| 圖二 |
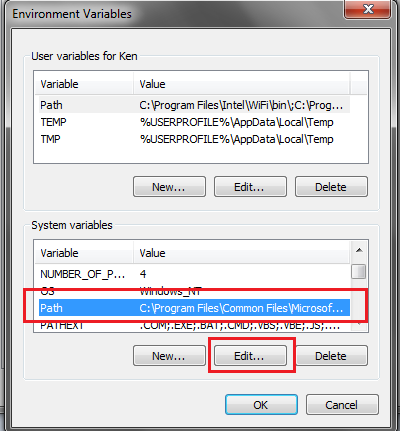
點選完成後,會看到下圖(圖三),請先找到Path這個系統變數,
並按下Edit按鈕。
 |
| 圖三 |
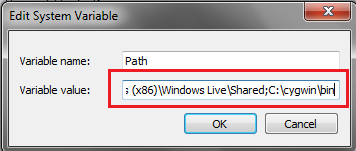
點選完以後,會看到下圖(圖四),
請在最後面增加";c:\cygwin\bin",
不需要雙引號喔!增加完成以後按下OK,請先重開機!
 |
| 圖四 |
【步驟三】設定Eclipse
設定完成以後,並且有把.jar檔放入eclipse/plugin以後,
請開啟Eclipse,
並點選Eclipse視窗中的右上角,如下圖(圖五)上方的框框,再點選other,
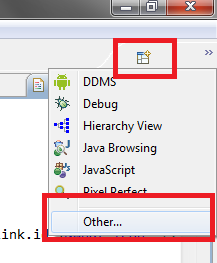 |
| 圖五 |
點選完以後,會看到下圖(圖六)
請選擇Map/Reduce,
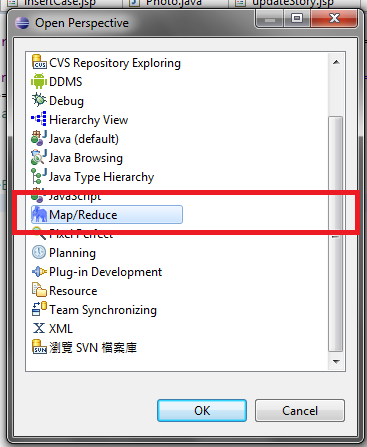 |
| 圖六 |
【步驟四】新增Map/Reduce Location
點選完成會看到下圖(圖七),
應該會有個Map/Reduce Locations的視窗,如左邊紅色框框,
此時請點選右邊紅色框框來新增一個Location
 |
| 圖七 |
點選完成會看到下圖(圖八),
就根據你們自己的位置輸入相關資訊吧!
那個user name並無大礙,填寫完成以後按下Finish。
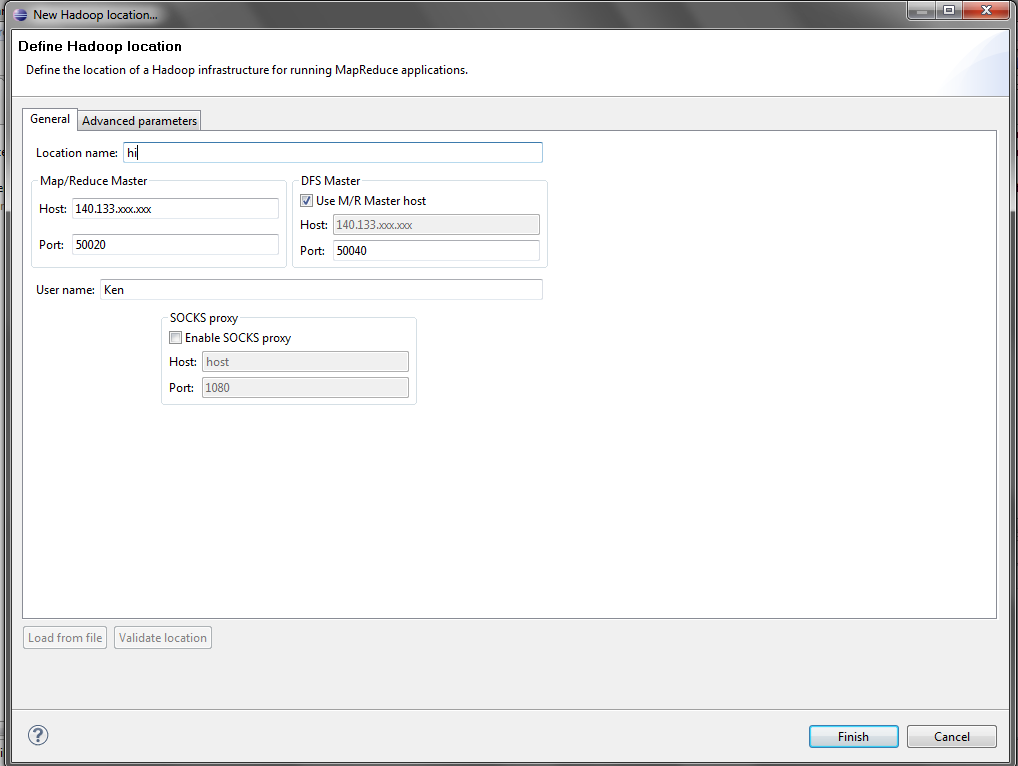 |
| 圖八 |
點選完成以後,會看到下圖(圖九)
會發現多了一個選項了,但是還沒完成喔,
我們在這個選項上點選右鍵,並點選Edit,
 |
| 圖九 |
【步驟五】設定Map/Reduce Location的參數
再點選上圖,圖八中的Advanced Parameters,來修改一些參數,
有些人可能會問,為什麼不一開始就修改,因為有些參數,必須先建立好第一步,
然後再進行修改它才會出現。
此時我們先找兩個參數,
第一個是dfs.permissions.supergroup,請修改成你能對server上的hadoop進行存取的群組,我的server上群組是hadoop,所以我會在這欄修改成【hadoop】。
第二個是hadoop.job.ugi,跟上面一樣,但請修改成【hadoop,Tardis】。
完成上面的步驟以後,
看到eclipse左邊的視窗,並點開DFS Locations,
會見到下圖(圖十),會發現你已經連線成功了,如果你是根據我這篇的安裝教學,你看到的資料夾名稱應該會是app,而不是appKen。
且不會看到user/hadoop/input這個資料夾,這個資料夾的功用是放置,程式將要讀取的資料。
將在下一篇,教導大家如何建立一個Map/Reduce專案。
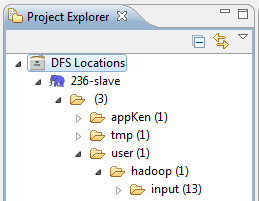 |
| 圖十 |
相關文章: